
3 способа вытащить текст из PDF-файлов или конвертируем PDF формат

Содержание
Всем добрый день!
Рассмотрев ранее, как можно создавать PDF-документ,
разными способами: и онлайн,
и оффлайн и даже средствами Microsoft Office, пришло время рассказать, как произвести
обратное действие.
Рассмотрим, как вытащить из PDF-документа текст, так
чтобы можно было потом его редактировать в Word и подобных ему текстовых
редакторах. То есть, попросту говоря, будем конвертировать PDF-файлы в Word.
Начнем!
Самый простой, быстрый и бесплатный вариант:
Открываем нужный PDF-документ в Adobe Reader. Заходим в меню Редактировать, потом выбираем команду “Копировать файл в буфер обмена”
Открываем нужный PDF-документ в Adobe Reader. Заходим в меню Редактировать, потом выбираем команду “Копировать файл в буфер обмена”

Дальше, стандартные действия: открываем Word, создаем
новый документ и нажимаем кнопку Вставить или воспользуемся быстрыми клавишами
(Ctrl+V).

Все, можно спокойно редактировать полученный текст.
Обратите внимание, при использовании данного метода не сохраняется
форматирование текста и нет возможности вытащить изображения!
Если вам, все таки, во что бы то ни стало нужно извлечь
изображение из PDF-документа, чтобы не использовать какие-нибудь
программы, сделайте скриншот с экрана на котором открыт PDF-файл, из которого
вы скопировали текст, но не получилось скопировать картинку.

И полученное изображение вставьте в Word. Должно
получиться вот так:

Понятно, что качество изображения будет оставлять желать
лучшего, но как запасной вариант вполне подойдет. В других просмотрщиках нужно
будет сделать несколько иное действие.
Вот так в Foxit Reader (меню инструменты –> команда
Выделить текст):

А
вот так в PDF-XChange Viewer (меню Инструменты –> Основные –> Выделение):

Затем выделяем нужный текст и производим стандартные
действия с буфером обмена, для тех кто не догадался: Копировать (Ctrl+C) и в
Word — Вставить (Ctrl+V).
Система
оптического распознавания текста (OCR)
При всей прелести этой методики у нее есть недостаток.
Конвертировать PDF в Word не получиться, если PDF-документ создан сканированием
с бумажного носителя или защищен от редактирования.
Поэтому будем использовать другой метод. А именно, с
помощью специальной программы оптического распознавания текста.
Программа называется ABBYY FineReader и, к сожалению,
является платной. Но зато функционал этой программы позволит перекрыть любые
требования по созданию и конвертированию PDF-файлов.
Вот, например, имеем отсканированный текст в PDF формате

Запускаем
ABBYY FineReader и в стартовом окне выбираем Файл в Microsoft Word

И
все! Система сама распознает текст и отправляет его в Word


Онлайн-сервисы
для конвертирования PDF-файлов
Вариант с онлайн-сервисами я уже описывал,
единственно, что могу добавить еще пару подобных сервисов:

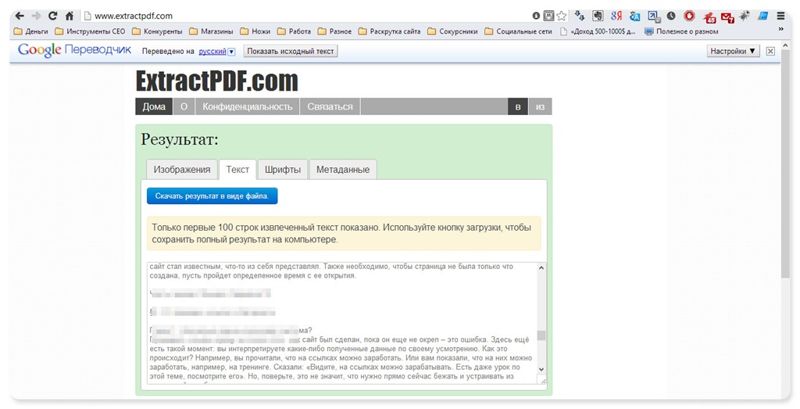
И опять же, ни один из онлайн-сервисов не работает с
изображениями, и если текст у вас отсканирован и сохранен в формате
PDF, то ничего не получится. Необходимо будет рассматривать вариант OCR.
Резюмируем
Как обычно, самым удобным оказался платный вариант, но
остальные имеют право на существование, потому что не каждый день требуется
преобразовывать файлы PDF. А на один раз можно или скачать демо-версию или
воспользоваться онлайн-сервисом.
Если нельзя, но сильно надо, то способ всегда найдется.
Да, и еще, если Вы знаете еще какой-нибудь способ
преобразования PDF-файлов, напишите мне в комментариях.
Благодарю за внимание!
Комментариев нет:
Отправить комментарий